
Organizations today have accessibility to greater data than ever. Thinking clearly of massive amounts of organized & unorganized data to execute organizational-wide improvements, on the other hand, can be incredibly difficult due to the enormous volume of data. If not addressed properly, this problem has the potential to reduce the value of all information.

This is the method through which companies discover trends in data to get conclusions pertinent to specific company objectives. It is vital for business intelligence as well as data science. There are several data mining strategies that businesses may employ to transform raw data into meaningful insights. These range from trying to cut AI technology to the fundamentals of data preparation, all of which are critical for optimizing the return of data initiatives.

What is data mining
Dismiss any overly technical definitions you may have associated with data mining and instead consider it for the rather simple notion that it is. Data mining is the technique of analyzing existing data from many viewpoints to turn it into knowledge that will be valuable in the administration of an organization & its activities.
Data mining may be defined as a technique that seeks to extract meaning from information by looking for trends & correlations to be utilized to make business choices.

For the rest of time, most people connected data mining with a group of high-end computers that use similarly high-end technology & programs to collect & analyze data. This isn't incorrect, because technology is a big and essential aspect of data mining. Nevertheless, data mining is a larger idea that goes beyond the application of technologies & comparable techniques.
One of the main explanations why many people are terrified by the slightest mention & concept of data mining is because it encompasses greater than either one or two fields. When we talk about data mining, we're talking about database administration and maintenance, which entails or requires the usage of database tools and technology.
As a result, it frequently involves deep learning as well as a high dependence on data science & technology.
Let’s check out some key points for a better return on your data mining initiatives..!

Cleaning and preparing data
Data cleansing and preparation are essential steps in the procedure of data mining. To be helpful in various analytic procedures, raw information should be cleaned & structured. Data cleaning & preparation encompasses data modeling, conversion, data migration, data integration, & compilation. It is a vital step in determining the optimal use of data by knowing its fundamental properties & attributes.
Data cleansing and preparation have obvious commercial benefits. Absent this first stage, information is either useless to an organization or untrustworthy owing to poor quality. Organizations should be able to rely on their data, the outcomes of their analytics, as well as the actions that emerge from those outcomes.
These processes are also required for data accuracy & effective data management.

Pattern recognition
Pattern recognition is a foundational data mining method. It entails discovering or analyzing patterns or trends in data to draw educated conclusions regarding business results. When a company recognizes a pattern in sales figures, for instance, there is a foundation for taking some action to capitalize on that knowledge. If it is found that a given product sells more frequently than rivals for a particular population, an organization can utilize this information to develop comparable items or services, or simply stock its actual product very effectively for this population.

Build An Engaging App For Free
Categorization
Data mining strategies for classification entail studying the numerous attributes associated with various sorts of data. Organizations can categorize or classify appropriate information after they have identified the primary features of various data kinds. This is crucial for recognizing individual information that businesses may want to safeguard or rescind from papers, for instance.

Association
Association is a statistical data mining approach. It denotes that some data are related to other information or data-driven event. It is analogous to the concept of co-occurrence in deep learning, which states that the existence of one data-driven event suggests the probability of another.
Resonance is a statistical term that is analogous to the idea of connection. This signifies that the analysis reveals a connection between 2 data occurrences, for instance, the observation that the buying of hamburgers is typically followed by the purchase of French fries.

Detection of outliers
Outlier identification identifies any irregularities in datasets. When businesses discover abnormalities in their data, it is simpler to determine why these abnormalities occur or plan for subsequent recurrence to best meet business objectives. For example, if there is a surge in the use of transaction processing networks for bank cards at a given time of day, firms may leverage this data by determining reasons why this is occurring to maximize their revenues for the remainder of that day.

Clustering
Clustering is a data analytics strategy that depends on visual techniques for data comprehension. Clustering algorithms employ images to depict the information's distribution concerning several sorts of metrics. Clustering algorithms also employ various colors to depict data dispersion.
Cluster analytics work well with graph techniques. Users may visually understand how data is dispersed using graphing & clustering in particular to uncover trends related to their business goals.

Regression
Regression methods are important for determining the structure of a dataset's connection between variables. In some cases, the links may be causative, while in others they may merely be correlative. Regression is a simple white box approach that illustrates how variables are connected. Prediction & data modeling both make use of linear regressions.

Prognosis
Forecasting is a strong feature of data mining and one of the four disciplines of analytics. Predictive analytics extends trends discovered in present and historical data into the horizon. As a result, it provides enterprises with insight into what patterns may emerge in their data in the future. There are various techniques to employ predictive analytics. Some of the most sophisticated utilize both artificial intelligence and machine learning. Nevertheless, prescriptive modeling does not have to rely on these approaches; it may also be aided by simpler algorithms.

Deriving patterns
This data mining approach focuses on discovering a set of events that occur in order. It's very handy for extracting transactional data. For example, after purchasing a pair of shoes, this approach can identify which articles of clothes clients are more inclined to acquire. Recognizing sequential data can assist firms in recommending more things to clients to increase sales.

Decision-making
Choice-making is indeed a form of a prediction model that allows businesses to successfully harvest data. A decision tree is technically a type of machine learning, however, it is more commonly referred to as a white box machine learning algorithm due to its simplicity.
A decision tree allows people to observe how the data inputs impact the outcomeshow the data inputs impact the outcomes. When many tree-based systems are joined, a predictive analytics model known as a random forest is created. Complex random forest models are referred to as black box machine learning methods since their outputs are not always straightforward to interpret based on their inputs. Nevertheless, throughout most circumstances, this fundamental kind of ensemble modeling is much more precise than utilizing decision trees alone.

Statistical methods
Statistical approaches are at the heart of the majority of data mining analyses. The many analytics models are founded on empirical (statistical) ideas that provide quantitative value relevant to certain business goals. In image analysis systems, for example, neural networks employ sophisticated statistics based on multiple weights and metrics to identify whether an image is of a dog or a cat.
One of the two major disciplines of AI is empirical models. Some statistical approaches use static models, but others, such as machine learning, improve over time.

Illustration (Visual illustration)
Another key aspect of data mining is data visualization. They provide customers with data insights based on sensory sensations that individuals can see. Data visualizations nowadays are dynamic, ideal for streaming information in real-time, or distinguished by distinct hues that highlight various patterns & trends in data.
Dashboards are an effective technique to identify data mining discoveries by utilizing data visualizations. Rather than merely employing quantitative outputs of statistical models, organizations may base dashboards on various indicators & utilize visualizations to graphically show trends in data.

Artificial neural networks
A neural net is a form of an algorithm for machine learning that is frequently used in conjunction with Artificial Intelligence & deep learning. Neural networks, so named because they comprise distinct layers that mimic how neurons operate in the neural network, represent one of the most precise and accurate machine learning algorithms utilized today.
Whilst neural networks may be an effective instrument in data mining, organizations must use them with prudence: Several of these neural network structures are quite sophisticated, making it challenging to grasp how a neural net generated an outcome.

Data warehousing
Data storage is an essential component of the process of data mining. Data storage used to entail preserving data sets in relational data management systems so that they could be evaluated for business analytics, reporting, or basic real-time reporting. There are now cloud data warehousing as well as data stores in semi-structured & unorganized data repositories such as Hadoop. Although data warehouses were typically intended to store historical data, several current techniques can do in-depth, real information analysis.
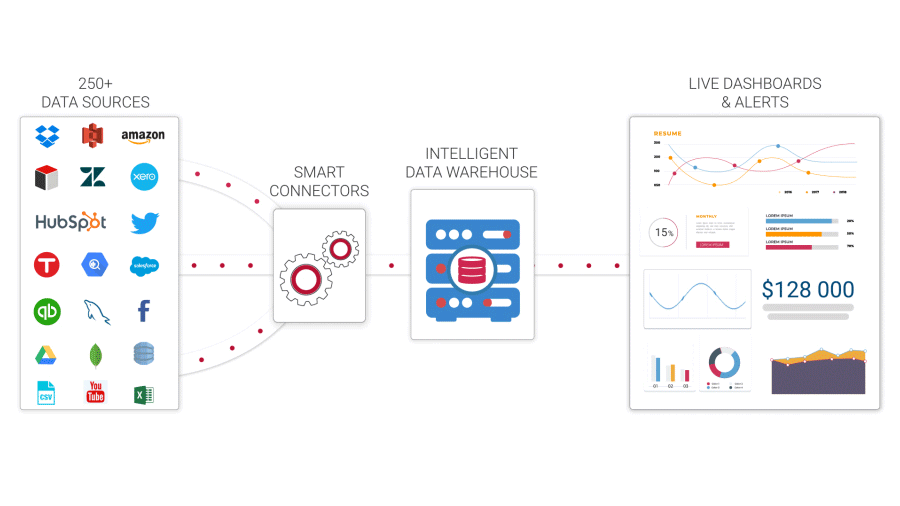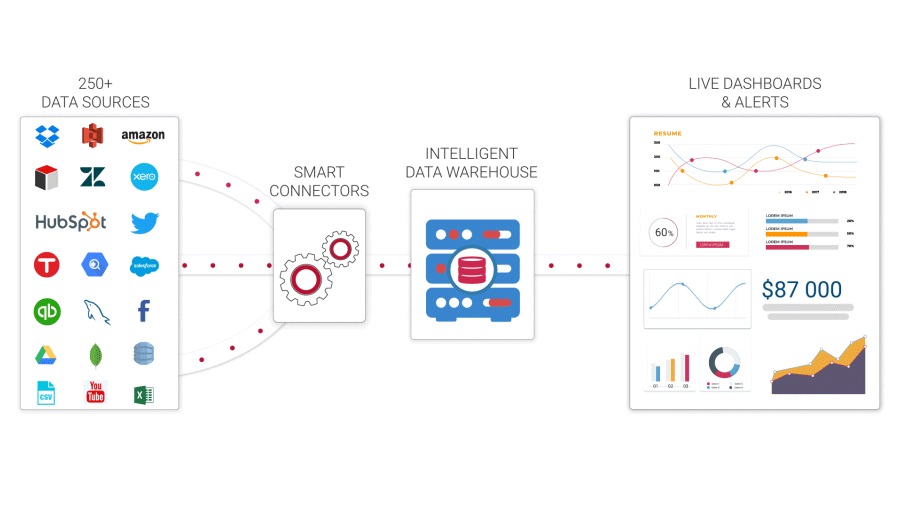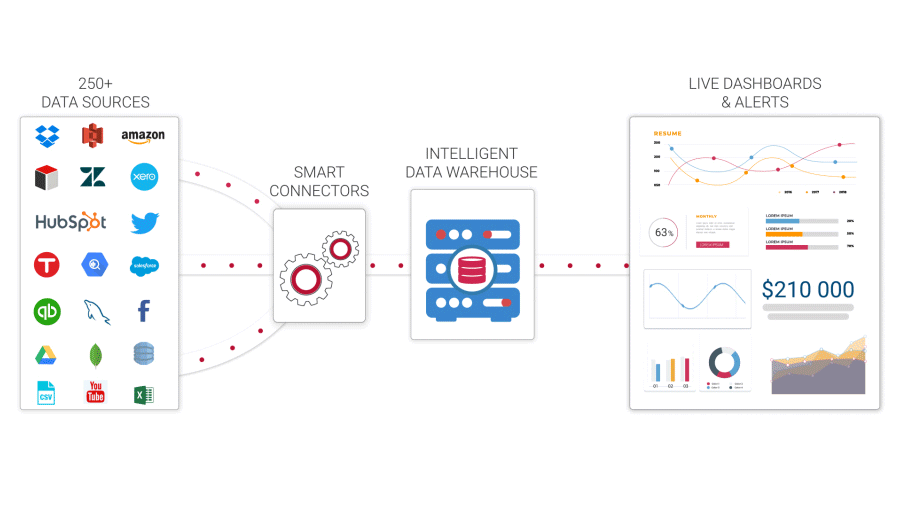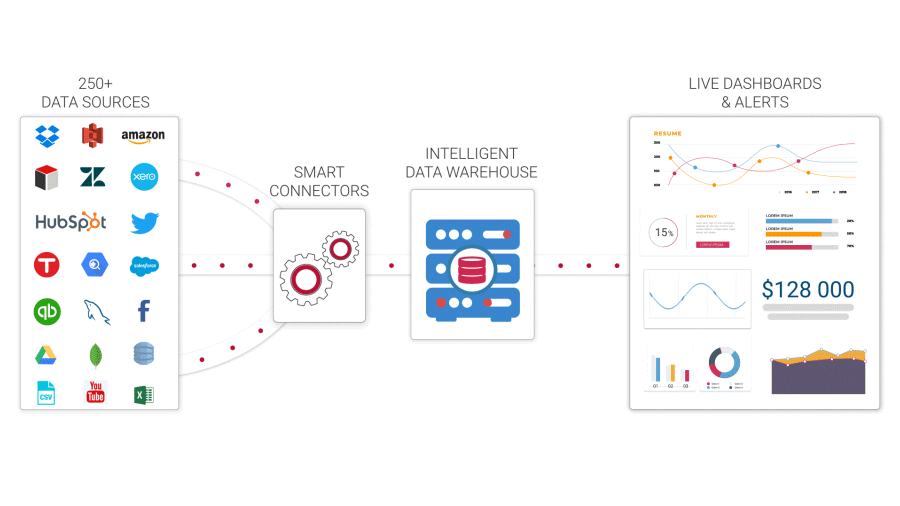
Processing of long-term memory
The capacity to interpret material over lengthy periods is referred to as long-term cognitive functioning. For this reason, historical data held in data stores is valuable. When an organization can undertake analytics over a long period, it can find trends that would normally be too minute to detect. For instance, a business may discover subtle indications of minimizing churn in finances by examining attrition rates over several years.
Artificial intelligence and machine learning
Machine learning and artificial intelligence (AI) are two of the most sophisticated data mining breakthroughs. When dealing with large amounts of data, sophisticated kinds of machine learning, such as deep learning, provide very precise forecasts. As a result, they're ideal for information processing in AI deployments such as machine vision, voice recognition, and advanced text analytics employing Natural Language Processing. These data mining approaches can extract value from semi-structured & unstructured information.

Data mining techniques for optimization
With so many approaches to choose from during data mining, it's critical to have the right tools to maximize your analytics. For successful implementation, these strategies typically need the use of many tools or technology with extensive capabilities.
Although enterprises can utilize data science tools including R, Python, and Knime for machine learning techniques, it is critical to use an information governance platform to guarantee adherence & appropriate data provenance. Furthermore, in addition to doing analytics, firms will need to collaborate with libraries such as cloud data storage, along with dashboards or data visualizations to give corporate users the data they need to comprehend analytics. Some tools have all of these characteristics accessible, but it is critical to find one.

Future of data mining
Technologies for cloud computing are having a significant influence on the expansion of data mining. Cloud solutions are perfectly adapted to the high-speed, massive amounts of semi-structured & unstructured information that most enterprises now deal with. The flexible resources of the cloud simply grow to satisfy these huge data needs. As a result, because the cloud can keep greater data in different formats, so much data mining technologies are required to transform that data into insight. Furthermore, sophisticated kinds of data mining, such as AI & machine learning, are available as cloud computing.



{kind=link}